Do you understand the pain when you have to train advanced machine learning algorithms like Random Forest on huge datasets? When there is a factor column that has way too many number of levels? When the time taken to train the model is so huge that you went to your pantry for snacks and came back, you are even done browsing 9gag but your model is still training, the code is still running? Fear no more, we will talk about these problems and how we can address them.
We will first try to understand why it takes so much time to train models on huge datasets in R. And then the solution to this - build models using H2O in R.
Our laptop has multiple cores in it. Most of the laptops these days come with at least 4 cores. R by default uses only one of the cores of your laptop. Say your laptop has 4 cores, then the remaining 3 cores are unused or may be partially used by other processes that your computer is running. Using just one core would obviously be slower than if R could use multiple cores in parallel.
What if R could use the other cores as well? This would definitely make the R codes run faster. The solution is H2o.
What is H2O?
H2O is The Open Source In-Memory, Prediction Engine for Big Data Science. H2o enables R to use the other cores of the laptop as well. R then runs on multiple cores of your laptop. You laptop is now like a standalone cluster. The power of you laptop has just increased by H2o. You know what your laptop is thinking right now - With great power, comes great responsibility.
Do you need to worry about how H2O converts your laptop to a cluster?
Not at all. It is as simple as running this - h2o.init(). We will come to this in later part of the post. The whole idea why h2o was built was keeping in mind that most of its users would be Data Scientists and it should be easy for them to build these models using h2o without any hassle of worrying about distributing the code across the cluster. And the developers of h2o have achieved this with flying colors.
Initializing the H2O cluster
So we now understand what is the use of h2o and how it can make our life easier. Let us now talk about execution. You would first need to install the h2o package using
install.packages(h2o)
Next, we load the installed package and launch h2o from R.
library(h2o)
local_h2o <- h2o.init()
The above will initialize your h2o cluster. Now there are other parameter in h2o.init() but for now let's go with the default settings. Few important parameters to h2o.init() are:
-
nthreads: Number of cores of the computer you want to use.
-
max_mem_size: The total RAM size allocated to the cluster.
If you are interested in the other input parameters that can be passed, you can read for help by typing ?h2o.init() in R.
Once you have initiated the cluster, check if your connection is working using h2o.clusterInfo().
You should see this line- R is connected to the H2O cluster along with other details of your initiated cluster. Now your cluster is ready and you are good to start your coding workflow in h2o.
Working with H2O
There are two ways you can work with h2o. Either with the flow or writing the code in R editor. The h2o flow is like an user interface that can be accessed at http://localhost:54321 after you have initiated the h2o instance using h2o.init(). The other way is to write the code in R. The serious work gets done by writing the code in R.
I normally use h2o flow just to create the first base model to see how the base model is doing. H2o flow is easy to get started with. There is no coding involved here. The image below shows the look of h2o flow. You parse in your datasets using the Data tab in the top right. The Model tab gives you a list of models you can train on your parsed dataset. The flow is pretty easy to go through.
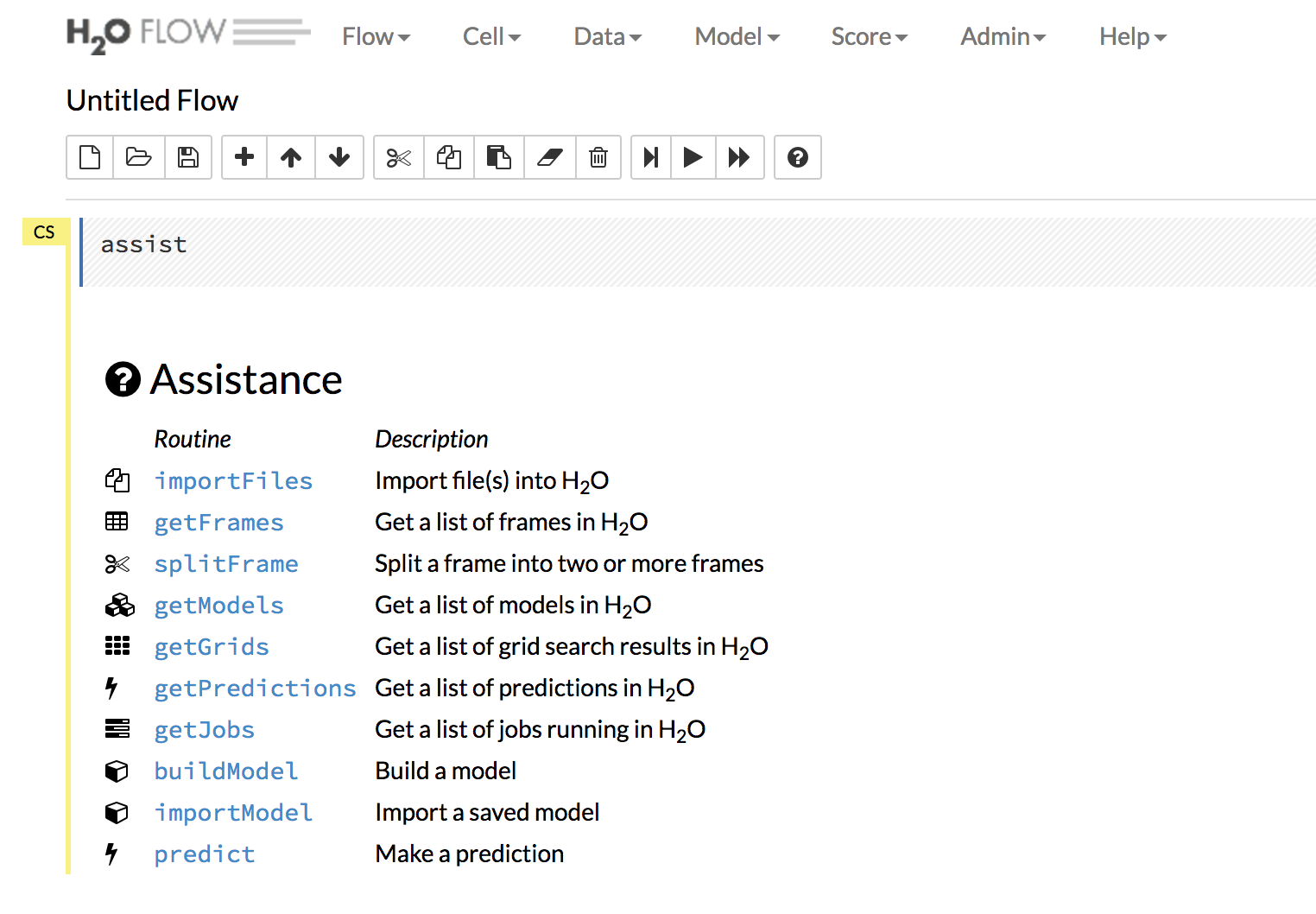
Almost all of the machine learning models are supported in H2o. Some of them being Deep Learning, Generalized Linear Models (GLM), Gradient Boosted Regression (GBM), K-Means, Naive Bayes, Principal Components Analysis (PCA), Principal Components Regression (PCR), Random Forest (RF) and few others.
Interaction of R with the cluster
-
The data is not saved in the R workspace. All data munging occurs in the h2o instance. By the look and feel it is easy to believe that all the processing is taking place in R but that is not true.
-
You are now not limited by R's ability to handle the data but by the amount of memory allocated to your h2o instance.
-
When the user makes a request, R queries the server via the REST API, which returns a JSON file with the relevant information that R then displays in the console.
Demonstration on a dataset
We will try to understand the working of h2o using a classification problem. The problem is simple. The government of a country wants to understand if its citizens are happy or not.
There are various independent features like WorkStatus, Residence_Region, income, Gender, Unemployed10, Alcohol_Consumption and a few others. There is a response column called Happy. Your task is to classify a citizen as happy or not happy. I will write a follow up post that will involve the code for the above problem statement.
As always, feedbacks and comments are welcomed. Share this with people who are interested in learning machine learning and data science. Let us talk more of Data Science.