There are two ways in which we can collect data for building recommender systems — explicit and implicit. In this post, we will talk about both types of data, their characteristics and the challenges with them.
Explicit feedback datasets
The dictionary meaning of explicit is to state clearly and in detail. Explicit feedback data as the name suggests is an exact number given by a user to a product. Some of the examples of explicit feedback are ratings of movies by users on Netflix, ratings of products by users on Amazon. Explicit feedback takes into consideration the input from the user about how they liked or disliked a product. Explicit feedback data are quantifiable.
But there are a few problems with explicit data. We will talk about them and then move to discuss the more abundant and easily available implicit feedback data.

Issues with explicit feedback data
When was the last time you rated a movie on Netflix? People normally rate a movie or an item on extreme feelings — either they really like the product or when they just hated it. The latter being more prominent. So, chances are your dataset will be largely filled with a lot of positive ratings but very less negative ratings.
Explicit feedback is hard to collect as they require additional input from the users. They need a separate system to capture this type of data. Then you’ve to decide whether you should go with ratings or like/dislike option to collect the feedback. Each having their merits/demerits.
Explicit feedback doesn’t take into consideration the context of when you were watching the movie. Let us understand with an example. You watched a documentary and you really liked it and you rated it well. Now, this doesn’t mean you would like to see a lot many documentaries but with explicit ratings, this becomes difficult to take into consideration. I like to binge watch The Office tv series while having dinner and I would give it a high rating 4.5/5 but that doesn’t mean that I would watch it at any time of the day.
There is another problem with explicit ratings. People rate movies/items differently. Some are lenient with their ratings while others are particular about what ratings they give. You need to take care of bias in ratings from users as well.
For me a good movie will be rated 3/5 but may be, for you, a good movie is rated 4/5 so clearly our ways of rating a movie is different and this bias needs to be taken care of.
We now understand explicit feedback and some of the issues with it. There is another type of feedback data in recommendation systems — implicit feedback. Let us talk about them.
Implicit feedback datasets
The dictionary meaning of implicit is suggested though not stated clearly. And that’s exactly what implicit feedback data represents. Implicit feedback doesn’t directly reflect the interest of the user but it acts as a proxy for a user’s interest.
Examples of implicit feedback datasets include browsing history, clicks on links, count of the number of times a song is played, the percentage of a webpage you have scrolled — 25%, 50% or 75 % or even the movement of your mouse.
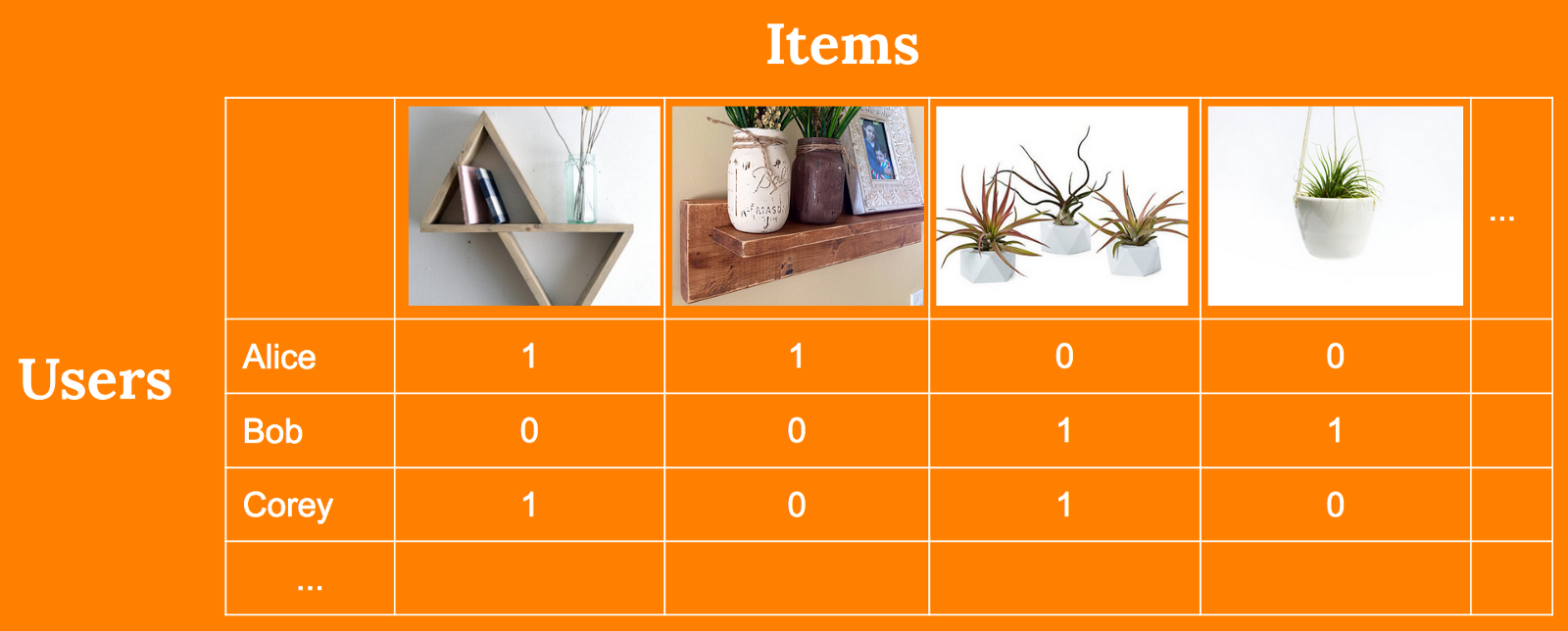
If you just browsed an item that doesn’t necessarily mean that you liked that item but if you have browsed this item multiple times that gives us some confidence that you may be interested in that item. Implicit feedback collects information about the user’s actions.
Implicit feedback data are found in abundance and are easy to collect. They don’t need any extra input from the user. Once you have the permission of the user to collect their data, your dependence on the user is reduced.
Let us talk about some unique characteristics of implicit feedback datasets:
- No negative preference measured directly
Unlike explicit feedback where a user gives a poor rating for an item, he/she doesn’t like, we do not have a direct way to measure the interest of a user. Repeated action in favor of the item — for eg. listening to Coldplay’s Fix You gives us confidence that the user likes this song and we could recommend a similar song to the user. However, an absence of listening count for a song doesn’t mean that the user does not like the item — may be the user is not even aware of the existence of the song. So, there is no way to measure negative preference directly.
2. The numerical value of implicit feedback denotes confidence that the user likes the item
For eg., if I’ve listened to Coldplay more number of times than that to Pink Floyd on Youtube, the system would infer with higher confidence about my likeability for Coldplay.
3. A lot of noisy data to take care of
You need to do a lot of filtering before you actually can get worthwhile data to be modeled upon. Just because I bought an item doesn’t mean I liked the item — may be I bought it for a friend or maybe I didn’t like the item at all after purchasing the item. To handle such issues, we can calculate confidence associated with the preference of the users for items. Read this excellent paper to get an idea of how to incorporate confidence in the feedback data — Collaborative Filtering For Implicit Feedback Datasets.
4. Missing values
Explicit feedback datasets are difficult to capture and hence a lot many values are missing and we go about modeling with whatever remaining ratings we have ignoring the missing values. While in the implicit feedback, we assign the missing values as 0 indicating no action from the user — no purchase or not listened to the song.
5. Evaluation of implicit feedback models require appropriate measures
With explicit feedback — eg. ratings of movies in Netflix data, one can use RMSE (Root mean squared error) as a metric to see how far the predicted ratings are from the observed ratings on a test dataset. With implicit feedback, such a metric is not available. We work with other metrics like decision-support based metrics — precision, recall or rank-based metrics like MRR (mean reciprocal rank), NDCG (normalized discounted cumulative gain), precision@k.
I know it may sound counter-intuitive when I say this — implicit feedback datasets are better than explicit feedback in general at getting improved recommendations. I don’t have a case study to prove this but I have listened to many talks of Xavier Amatrian, a great name in recommendation systems domain and I’ve heard him iterate this point many times.
So, there we have the types of data we generally deal with while building recommendation systems. Let me know your thoughts!